文字分析平台-使用說明
服務網址
文字分析平台是對文字資料進行簡易蒐集、處理與分析的工具。
- 本頁的教學目的是要讓使用者了解,利用文字分析平台分析文字資料時,使用的順序為何以及哪些地方要注意。
- 透過平台,使用者可以自己上傳CSV資料集,也可以對PTT討論板、Dcard看板,或是聯合、蘋果、中時、東森等新聞來源進行爬蟲。
- 可由此連結查看目前各來源、各類別、各年度/月份的資料數量。
- 平台利用管院提供的平行運算資源,讓使用者快速地對文章做斷詞斷句及其他標注處理。
- 透過平台處理完後的資料,可以根據使用者的需求實現資料視覺化,也可以將資料下載成CSV檔輸出,以便後續在RStudio上執行更進一步的分析。
- 欲使用本平台請先至帳號申請,核准後將予以一組帳號,即可使用文字分析平台。
影片教學
平台使用步驟
首先,輸入申請到的帳號密碼登入平台。
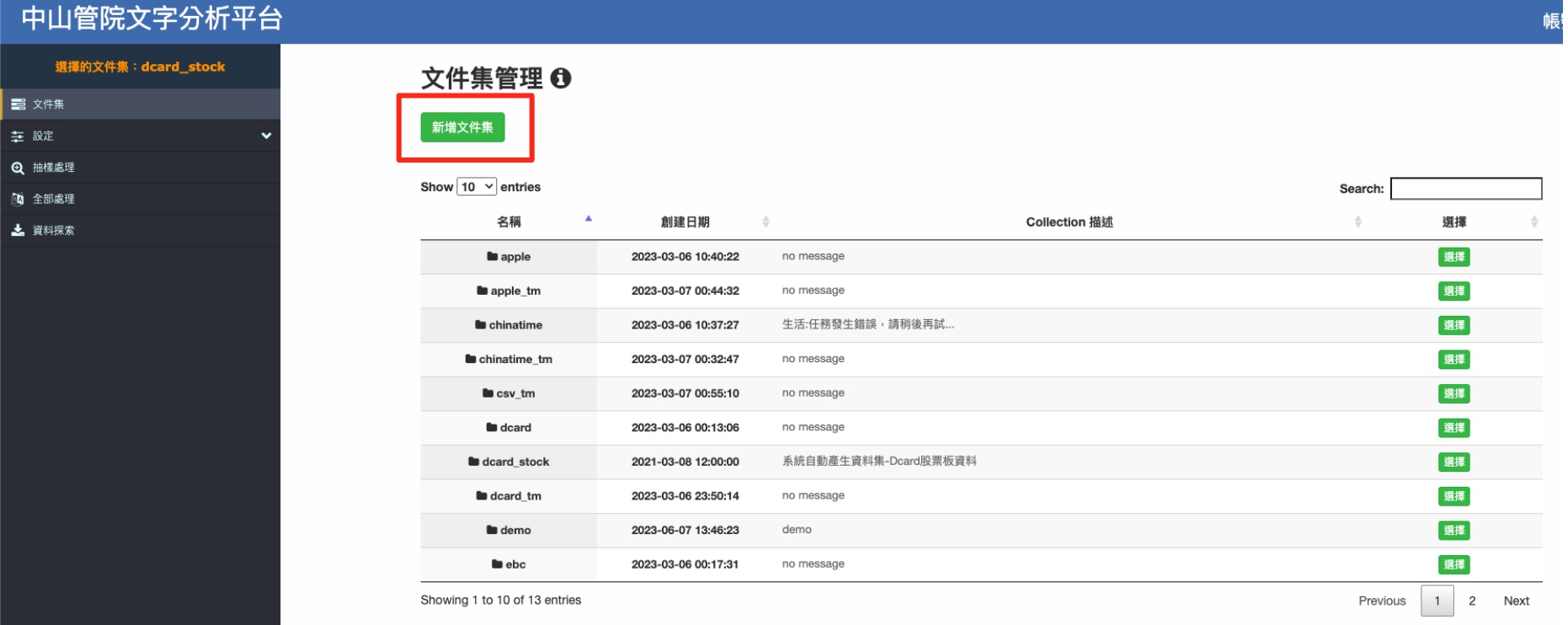
進入主頁後,點選『新增文件集』。
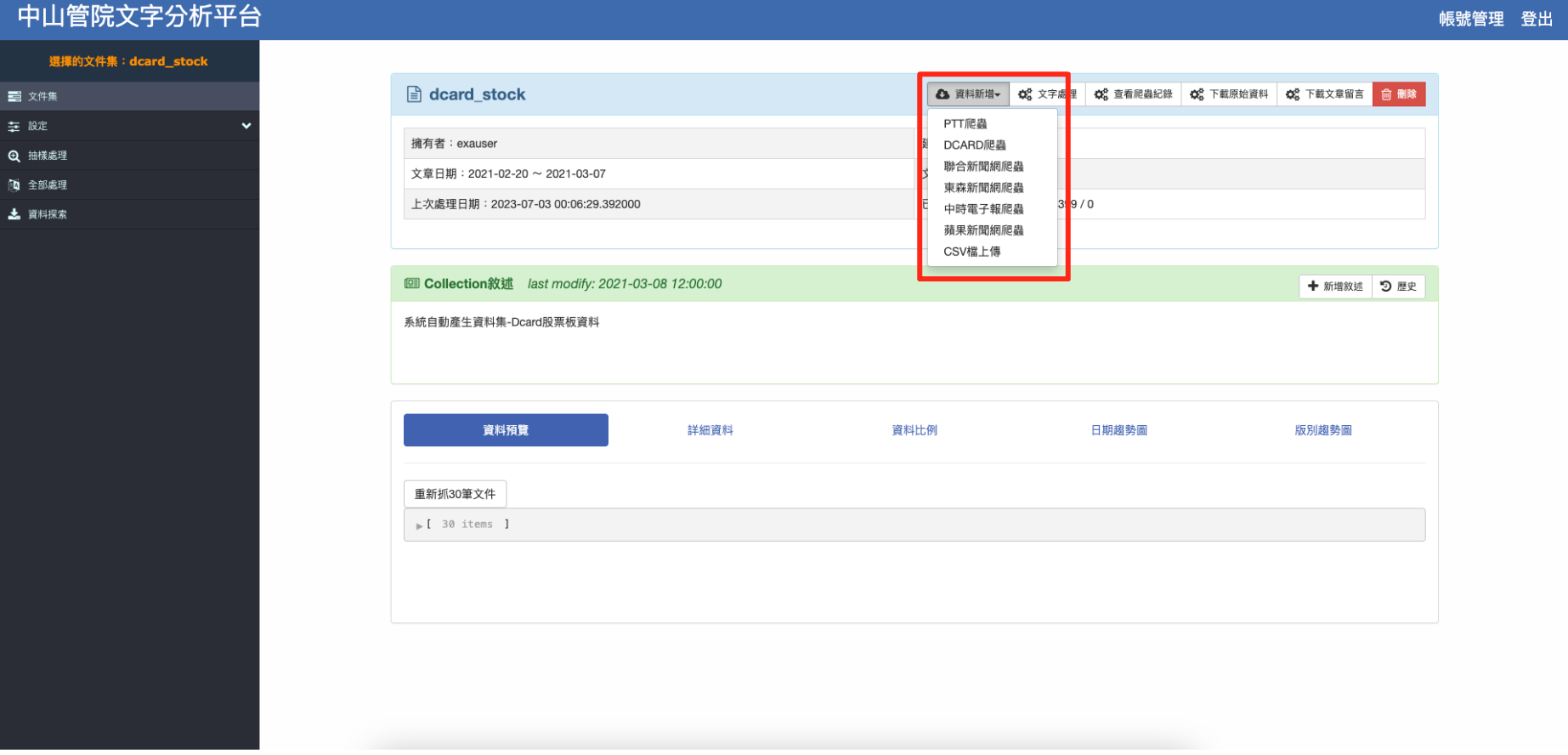
建立文件集後可在其中加入資料,您可以上傳自己的CSV資料檔,也可以對PTT討論板、Dcard看板,或是聯合、蘋果、中時、東森等新聞來源進行爬蟲。本範例以PTT爬蟲為例。
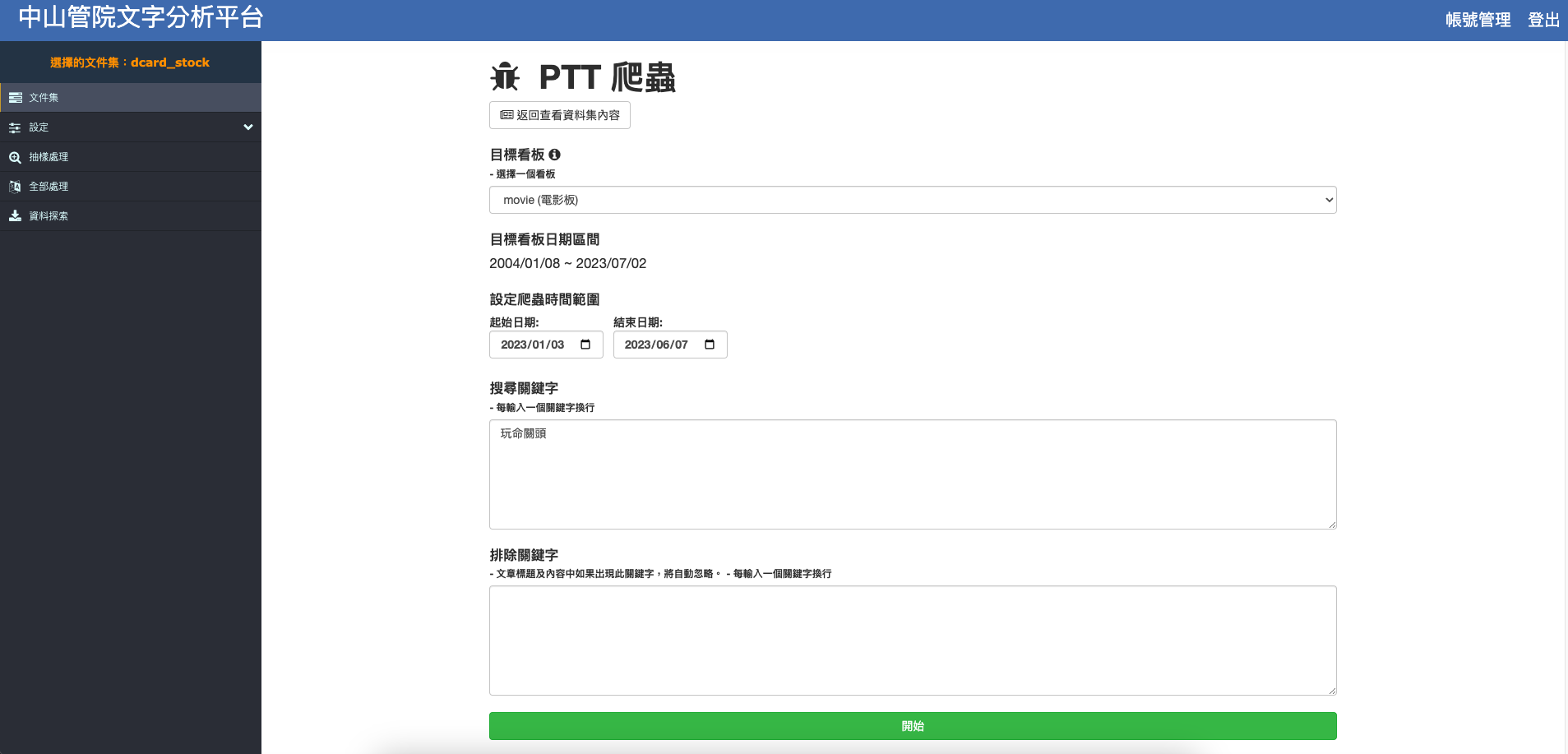
輸入想要抓取資料的看板或類別,下方會自動跳出目前資料庫內所擁有資料的時間範圍,之後選擇開始與結束日期並輸入要搜尋與排除的關鍵字(可輸入多個關鍵字,請以換行分開每個關鍵字),最後按下開始按鈕即可開始爬蟲。
爬蟲完成後,點選查看爬蟲結果,資料預覽可初步瀏覽所抓取資料的結構與內容,資料分布可觀察資料的時間分佈,接著點選右上角『文字處理』進行下一步動作。

進入後可開始調整文字處理參數,語言目前只支援中文。
- 字元替換可將特定字元替換為句號(句子分隔使用)及逗號,可輸入正規表示式,預設內容為PTT文章常使用的規則。
- 保留數字與英文字母可是需求勾選,未勾選則會刪除。
- 自訂辭典進入後可新增辭典,定義詞彙權重,高權重詞彙會被優先斷詞。
- 例如,原先斷詞結果為[“玩命”, “關頭”, “超”, “好看”]
- 加入詞彙:玩命關頭 50
- 斷詞結果將變為[“玩命關頭”, “超”, “好看”]
- Sample Process 將抽取少量樣本進行處理試做,可測試參數調整是否符合需求。
- Full Process 將處理所有文章,需耗費較長時間,請調整好參數後再進行。

點選Sample Process可進入抽樣處理頁面。
畫面中的紅色框框裡,分別有文章斷句、文章斷詞、詞性標注以及重新抽樣的按鈕,其功能為以下:
- 文章斷句 會將文章每個句子分開
- 文章斷詞 會將句子分割為各個詞彙
-
詞性標注 可為各個詞彙標記詞性
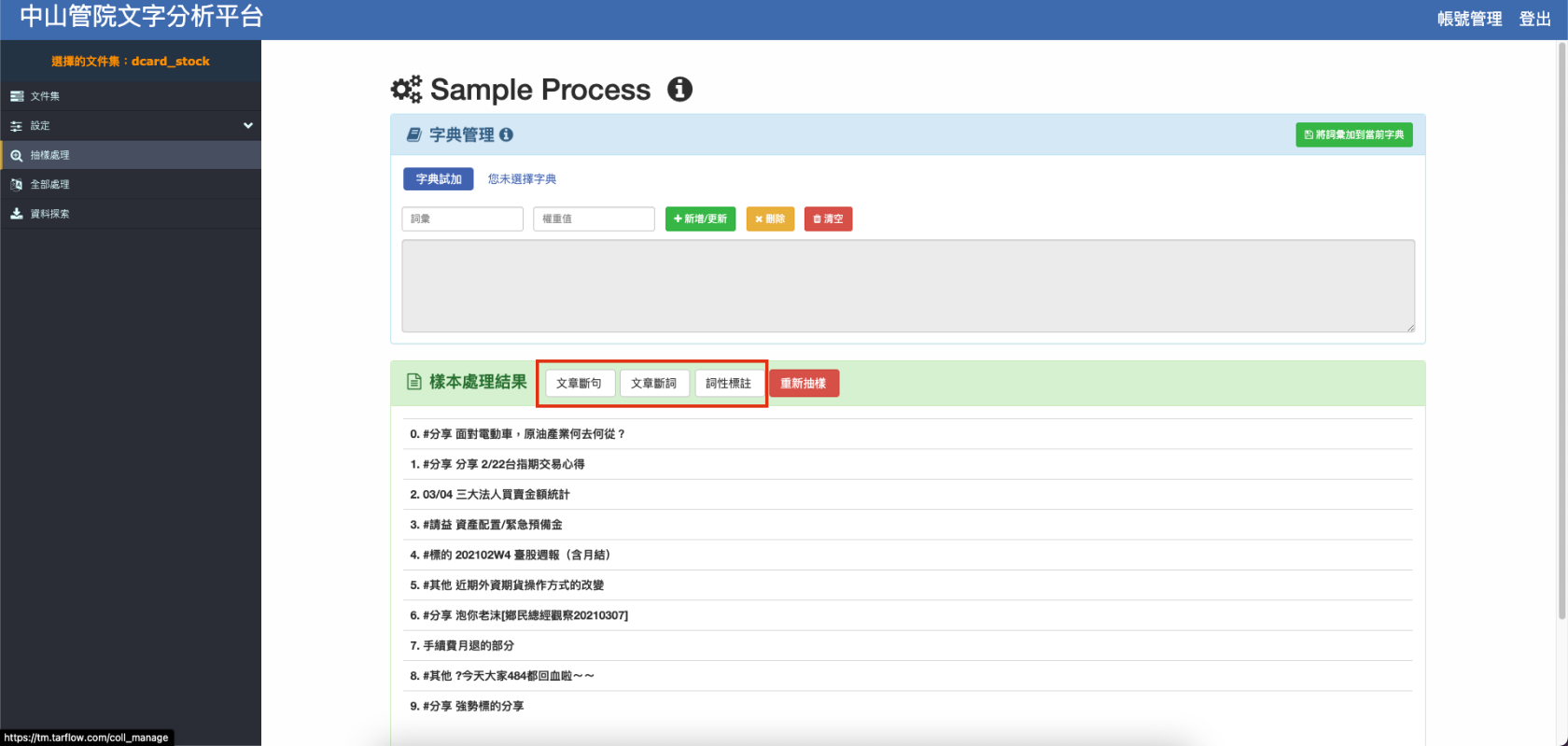

- 點選樣本可看見上述動作執行結果,例如做完詞性標注之後
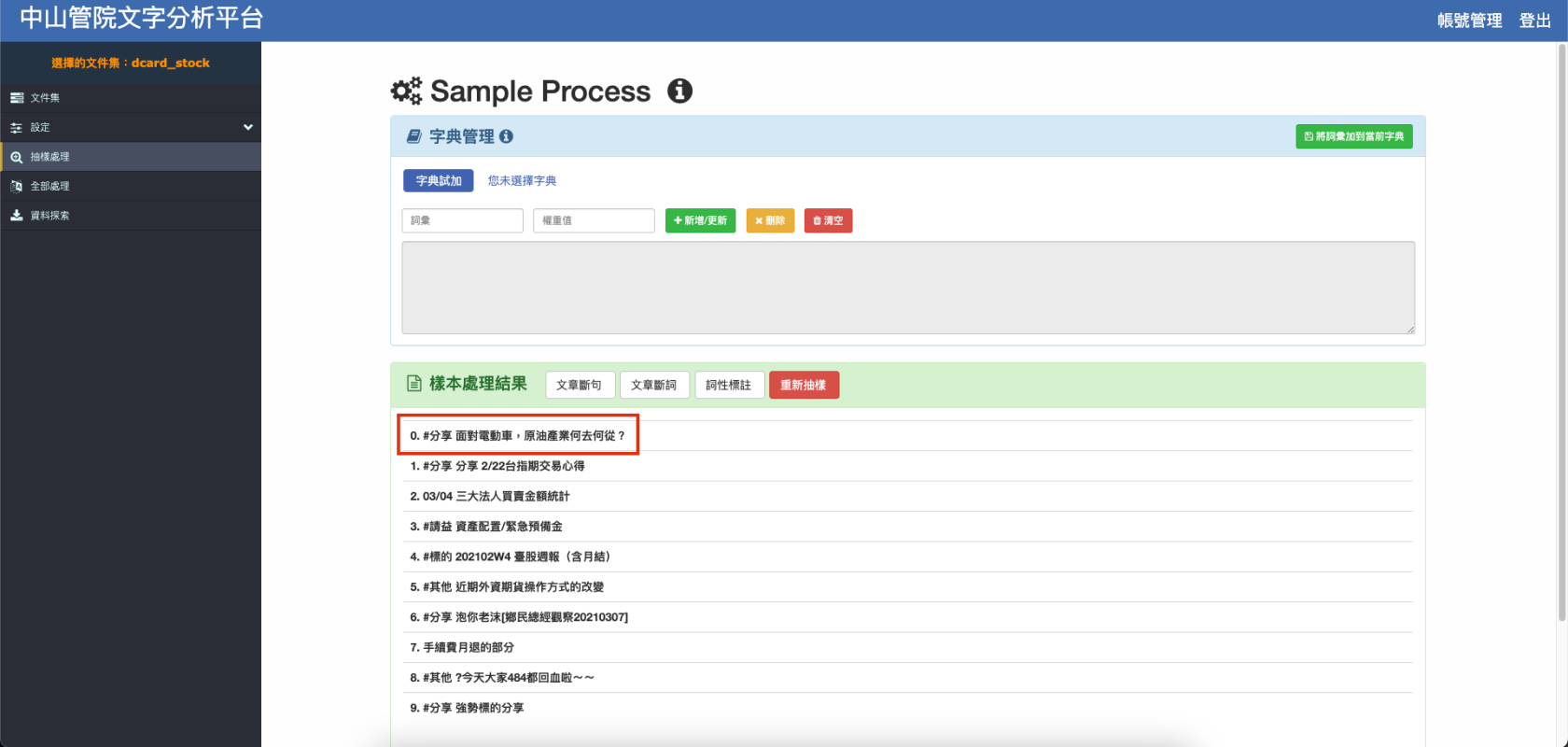



- 詞彙權重可直接更動以測試不同結果,請根據顯示的結果去新增想要斷在一起的詞彙。
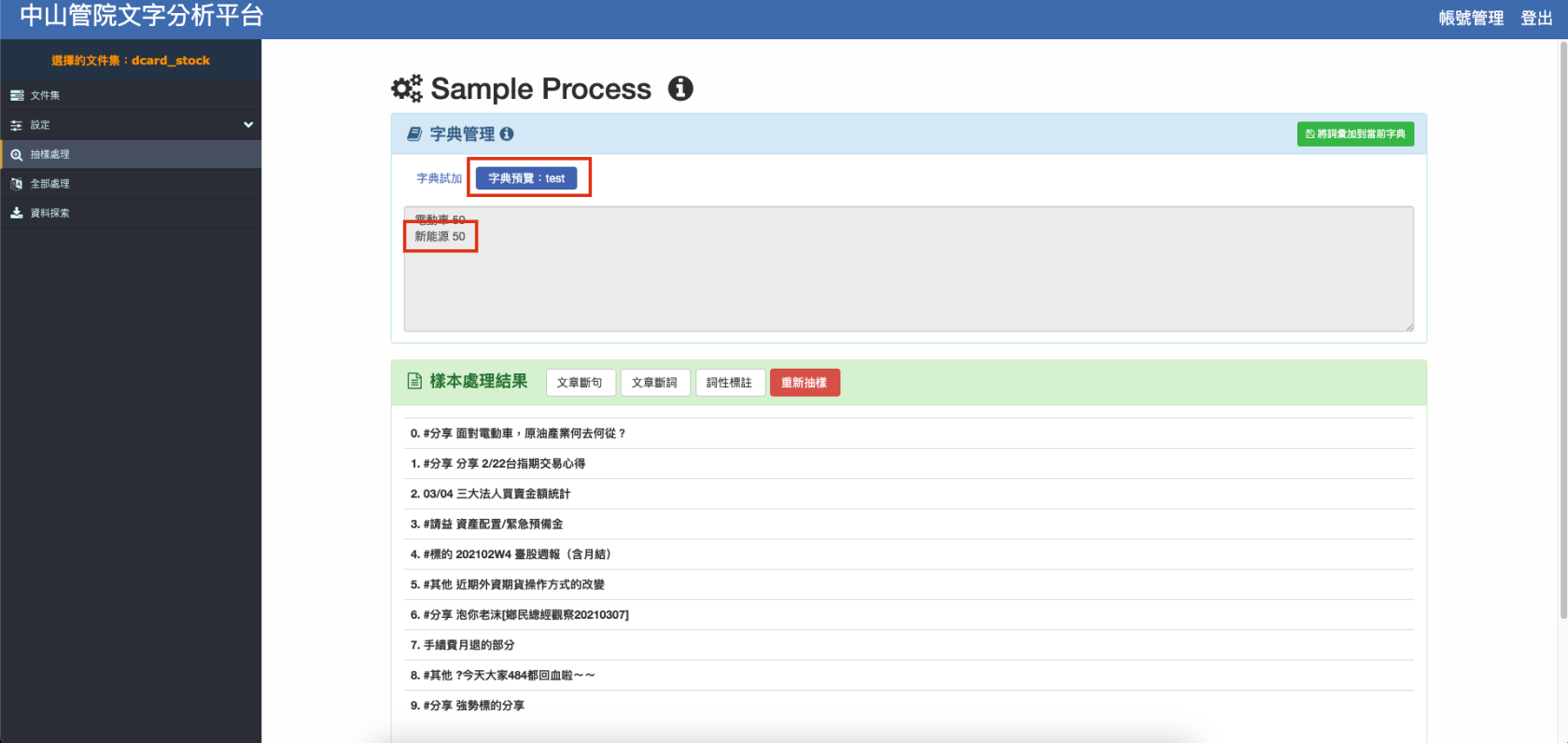
例如想把「新能源」斷在一起,就可以在『詞彙』以及『權重值』的輸入框中輸入「新能源」及權重植(eg. 50),再重新執行文章斷詞 就可以查看是否有成功斷在一起,若沒有可以嘗試提高權重值。

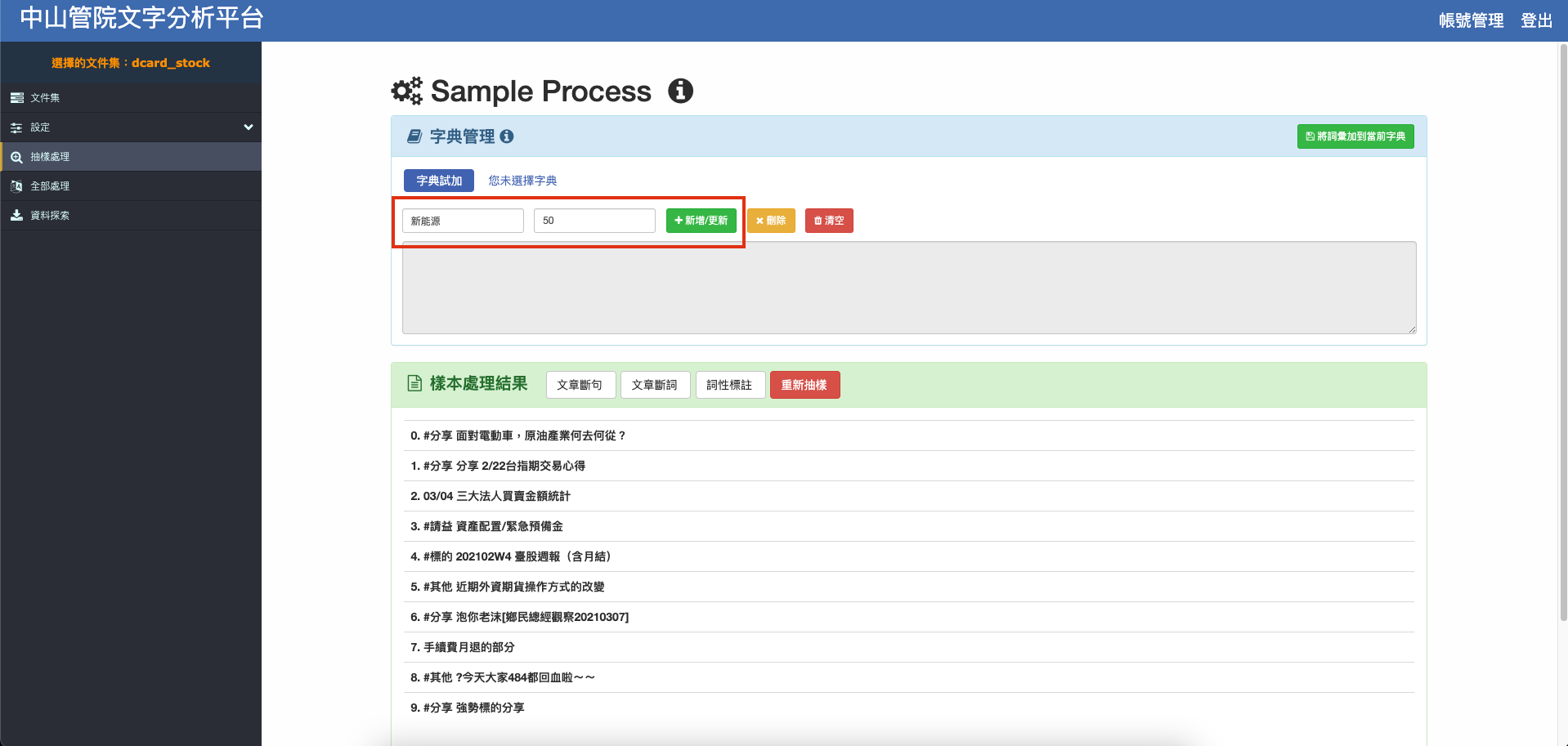


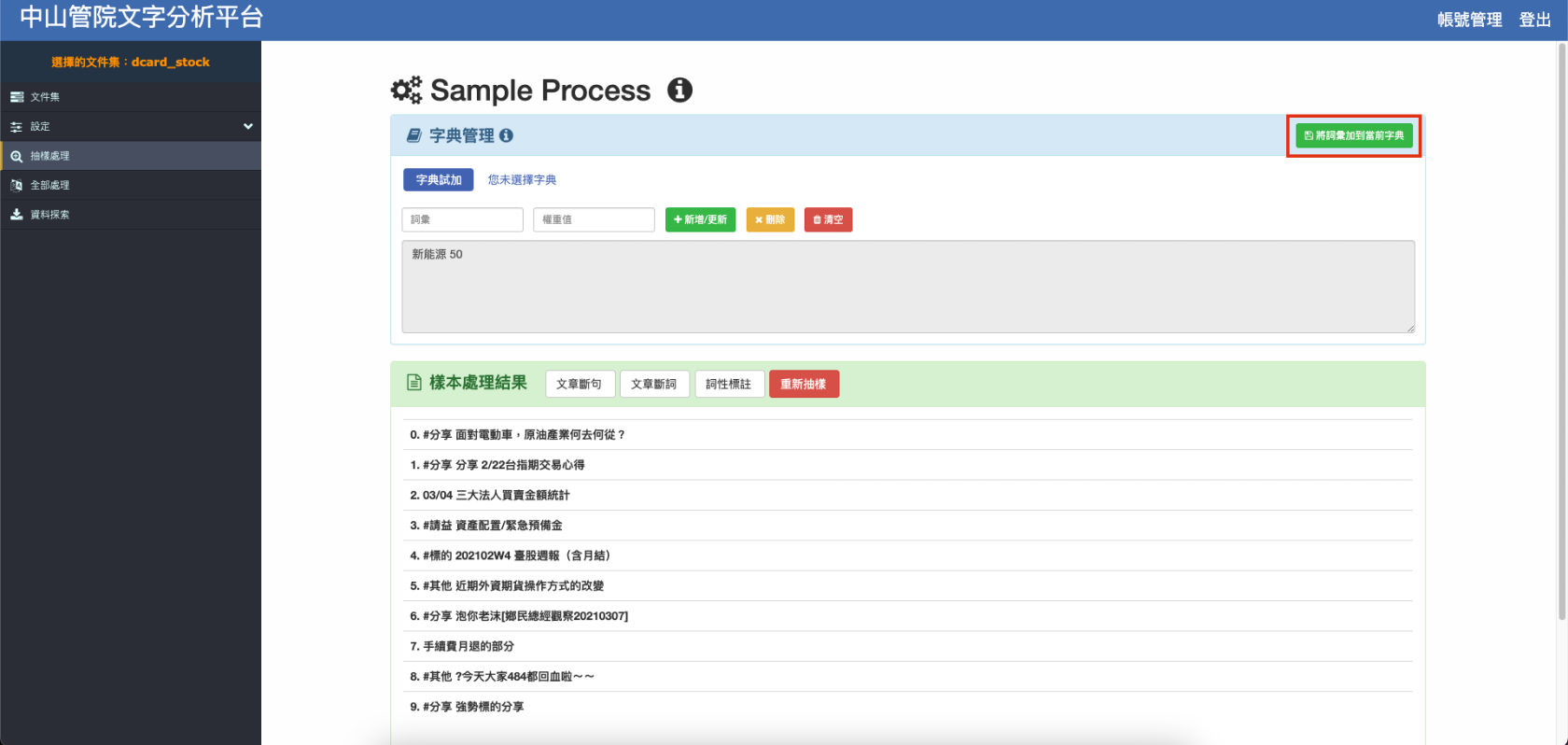
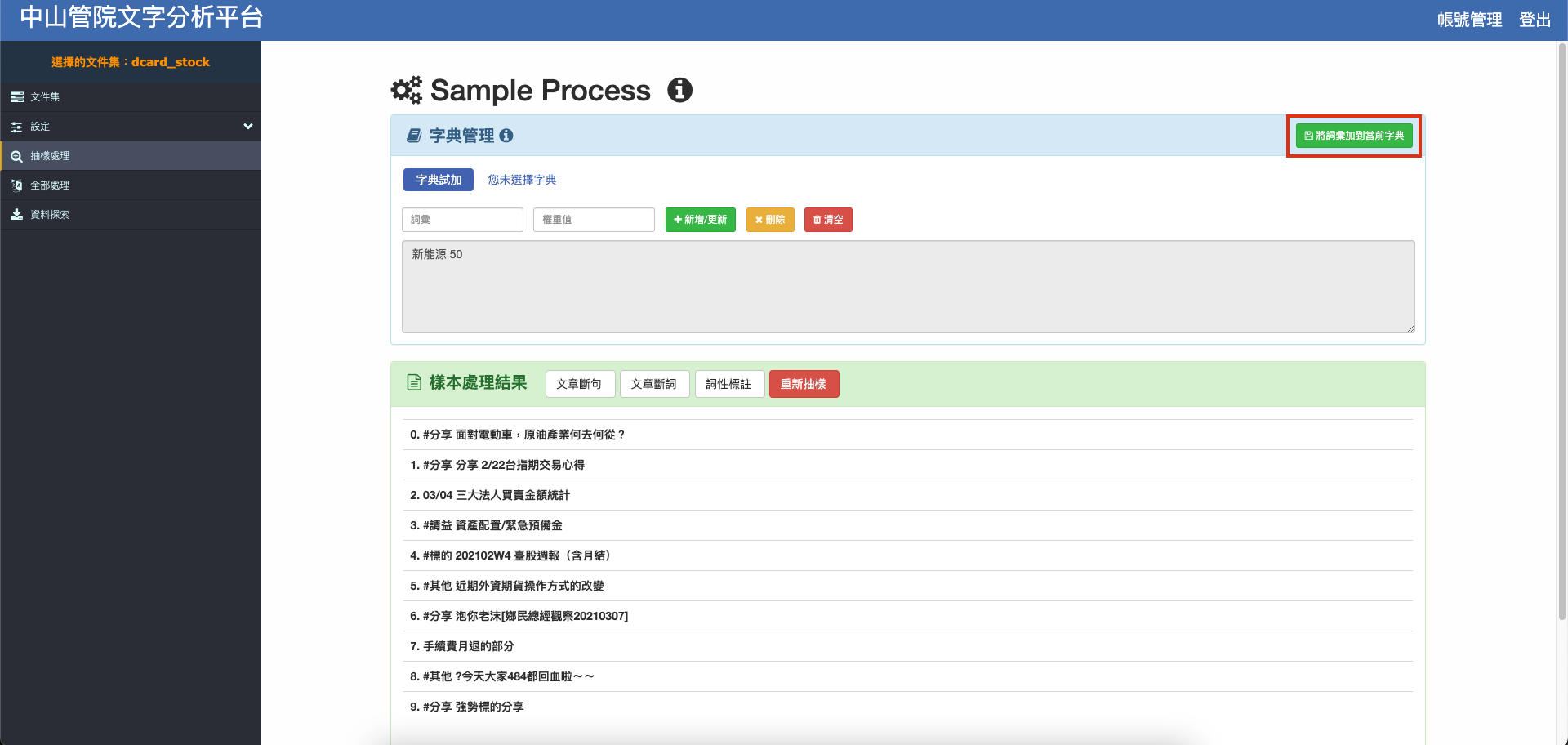
調整完畢請務必點選右上角加入辭典,否則不會更新至辭典

若需更改斷句符號,可點選左側 設定 → 文字處理參數
在Sample Process調整好參數後,點選左側全部處理,點選執行,便可進行所有資料的處理,完成後即可點選該資料集右方的『查看』按鈕查看視覺化圖表資訊,並根據視覺化圖表的結果重新調整參數設定。

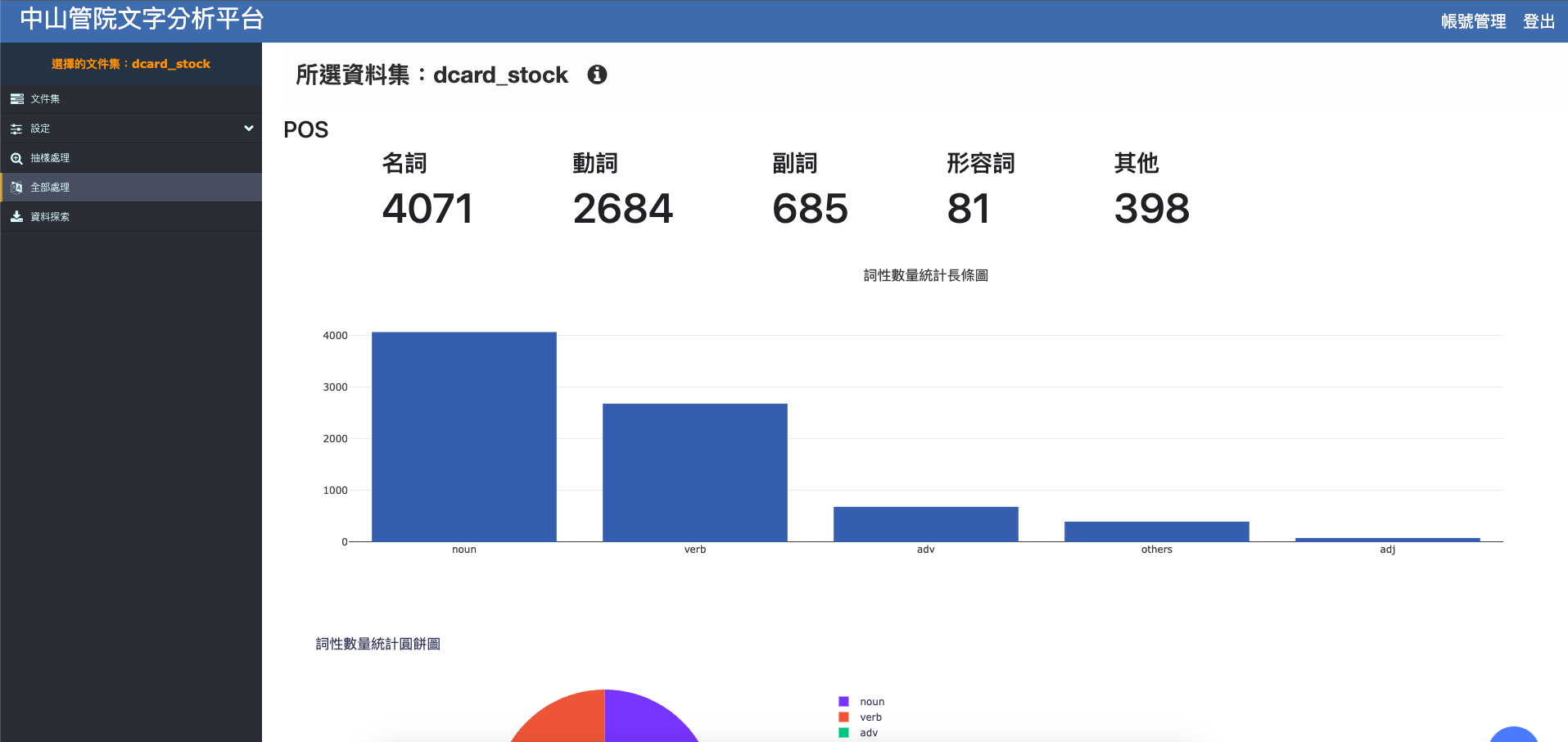
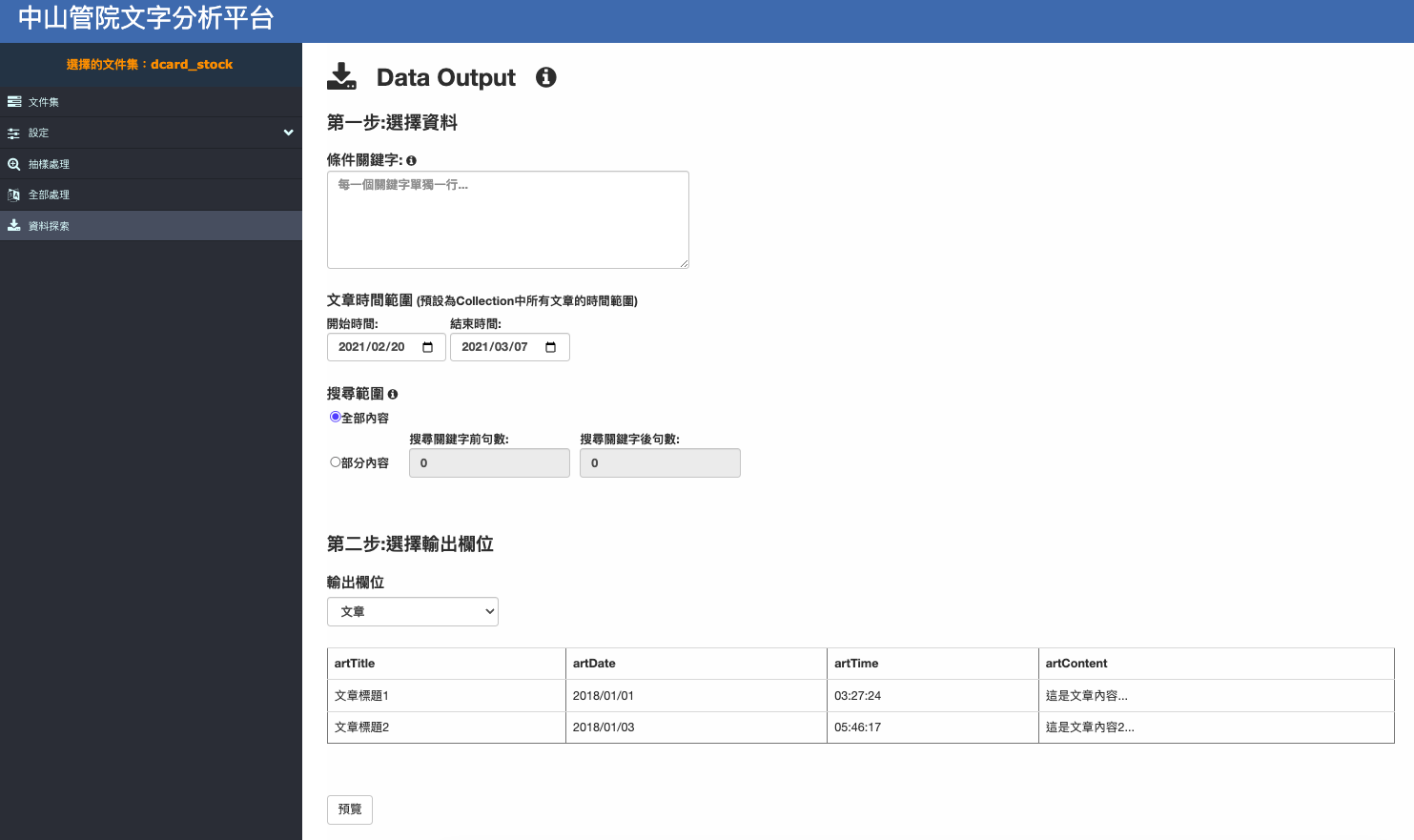
沒問題後就可以點選左側資料探索,即可依據需求輸出各種的CSV檔案。
- 條件關鍵字:只提取內容包含關鍵字的文章,以換行分隔多個關鍵字,若空白則提取所有文章。
- 文章時間範圍:只提取發文時間在選擇範圍內的文章
- 搜尋範圍:可只針對關鍵字的前後句來進行輸出
- 選擇輸出欄位:可依據不同需求,輸出不同格式的資料
- 類別:只輸出已選擇的文章類別
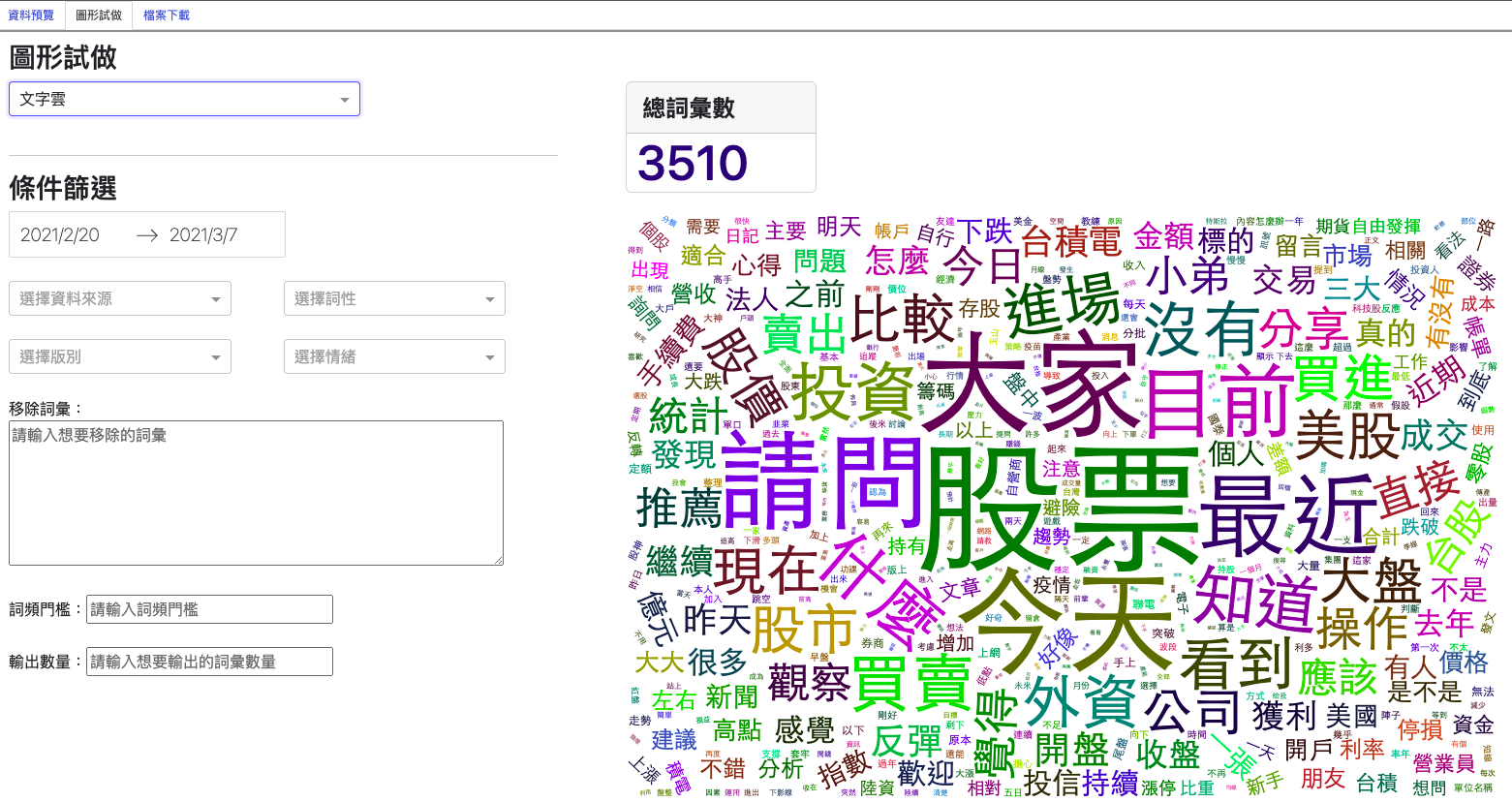
點選預覽可檢視資料,根據不同格式,可以有不同的圖形試作。 最後點選檔案下載,即可得到處理好的文字資料CSV檔案。
資料後續分析範例
以下範例是透R語言執行
- 首先,載入需要的library
library('data.table')
library('text2vec')
library('later')
- 接下來,讀取檔案(文章詞彙格式),將資料處理成文章對應所有出現詞彙的格式
data <- fread("Ma_artWord.csv",encoding = "UTF-8")
column <- names(data)[1:ncol(data)]
temp <- data[1]$artTitle
mystr = "" # Set default String
text = c()
id = c()
id <- append(id, temp) # Set start title_id
str_vec = c() # word segmentation in one document
tokens = list() # word segmentation for each documents
for(i in 1:nrow(data)){
# the same document
if(data[i]$artTitle == temp){
mystr <- paste0(mystr, data[i,5], " ")
str_vec <- c(str_vec, unname(unlist(data[i,5])))
}else{
id <- append(id, data[i]$artTitle)
text <- append(text, mystr)
mystr = ""
tokens[[temp]] <- str_vec
temp <- data[i]$artTitle
str_vec = c()
}
}
text <- append(text, mystr)
tokens[[temp]] = str_vec # append the last document
post <- data.frame(id, text)
doc.list <- tokens
- 將刪除出現次數過少的詞彙並製作詞彙與對應編號陣列
term.table <- table(unlist(doc.list))
term.table <- sort(term.table, decreasing = TRUE) # sorted by term frequency
del <- term.table < 5| nchar(names(term.table)) < 2 # term frequency < 5 or len(term) <2
term.table <- term.table[!del]
vocab <- names(term.table)
- 文字轉換為編號
get.terms <- function(x) {
index <- match(x, vocab)
index <- index[!is.na(index)]
rbind(as.integer(index - 1), as.integer(rep(1, length(index))))
}
documents <- lapply(doc.list, get.terms)
- 設定LDA參數
K <- 25 # Topics
G <- 5000 # iteration times
alpha <- 0.10
eta <- 0.02
- LDA學習
# LDA
library(lda)
set.seed(357)
fit <- lda.collapsed.gibbs.sampler(documents = documents, K = K, vocab = vocab, num.iterations = G, alpha = alpha, eta = eta, initial = NULL, burnin = 0, compute.log.likelihood = TRUE)
theta <- t(apply(fit$document_sums + alpha, 2, function(x) x/sum(x))) # Doc—Topic distribution matrix
phi <- t(apply(t(fit$topics) + eta, 2, function(x) x/sum(x))) # Topic-Word distribution matrix
term.frequency <- as.integer(term.table) # Term-Frequency
doc.length <- sapply(documents, function(x) sum(x[2, ])) # length of each Doc
- 結果視覺化,此套件以網頁瀏覽器呈現,可使用Safari及Firefox開啟,當程式結束,可在該產生資料夾中開啟index.html,即可呈現結果。
# LDAvis
library(LDAvis)
json <- createJSON(phi = phi, theta = theta,
doc.length = doc.length, vocab = vocab,
term.frequency = term.frequency)
serVis(json, out.dir = './vis_25_topic', open.browser = FALSE)

聯絡我們/問題回報
- 若有任何問題,歡迎透過問題回報來回覆我們,讓我們可以進一步優化系統。